
Good data is the basis for good science and reliable results. It is important for your research platform to collect, validate, curate, analyze, communicate, and secure your data.
By following proper data management practices, you’re ensuring the results of your study are high quality, valid, accessible, and sustainable.
To generate high-quality data for your study, it’s essential to have centralized data curation that allows the study team to validate and analyze the data as the research progresses.
The use of standard and custom data queries enables the team to examine large sets of data and look for patterns. Any data issues discovered by these queries will go back to the sites to fix questionable data. The curation team will close the loop in a timely manner, determining if the site resolution was reasonable. This feedback loop can be used to determine where sites might need more training or where a study process or form needs to be adjusted to more efficiently capture the data.

Data Curation in TBI Research
In short, data curation is defined as the process of evaluating, validating, and enhancing collected data to optimize its use. In simpler terms, it’s when someone takes a look at the collective study data and verifies that it makes sense. We want to be scrupulous about collecting and verifying data – knowing that the study data may come from many different sources:
- EHR (Electronic Health Records)
- eCRF (electronic Case Report Forms)
- ePRO (electronic Patient Reported Outcomes)
- etc.
When it comes to traumatic brain injury (TBI) studies, we like to think of curation as the process of ensuring the data capture is as complete and accurate as possible. It’s a process and communication between the centralized curation team and the people entering the data at the TBI clinical research sites.
Example 1:
In a large nationwide study, the centralized data curation team found that several baseline assessments, foundational to the study, were missing for a large number of patients at certain sites. The curation team reached out to the sites to have them change their data collection process, so the optimal data were collected. Missing or incorrect critical data that is not captured correctly and in a timely manner can invalidate the data of a participant and eliminate that person from the cohort. Scientific studies can’t afford to have participants eliminated for missing data.
Example 2:
At a meeting, one of the analysts from a large international TBI study was talking about the GOSE, which is a scale of how functional someone is after an injury. It goes from a score of 1 (dead) to 8 (upper good recovery). In their data curation process, they noticed that there were no 1s in the data. It seems obvious, but people who are dead are not assessed, and no data is captured.
Ultimately, the best curators work in lockstep with each research site to help them fix questionable data, and make sure they ‘get it right.’
The Importance of the Right eCRF Setup
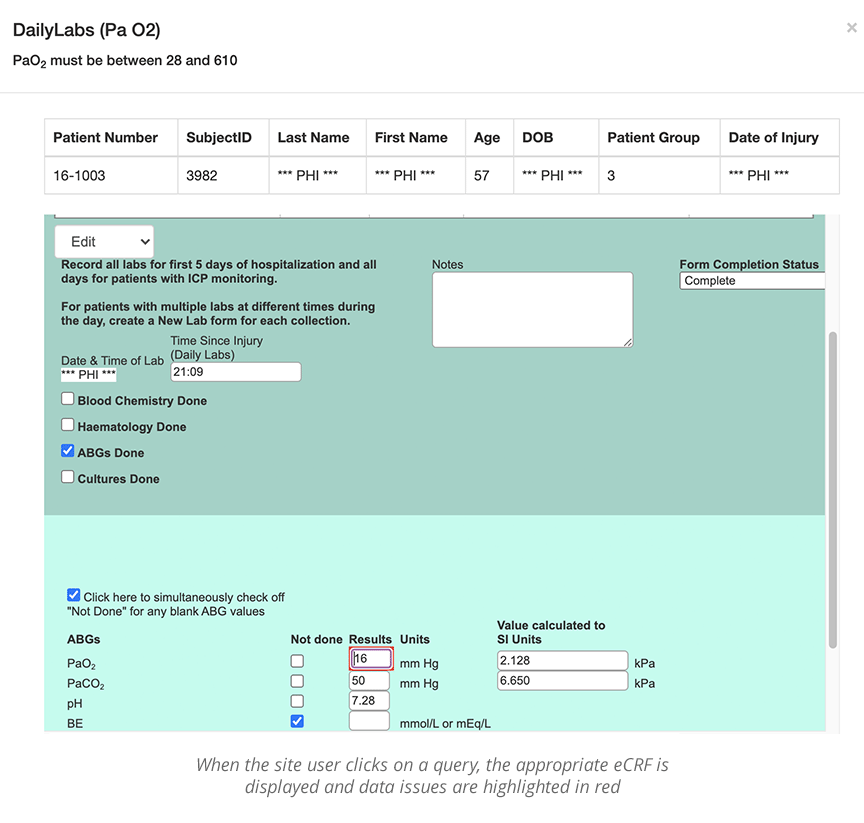
Data curation starts with setting up your electronic case report forms (eCRFs) to ensure the fields you create are in the right format and are validated for accuracy. Dates, free text, integers, decimals, and so on, are all “types” of data that need to be specified when developing the electronic case report form. The rules you create for entering data will prevent the introduction of ‘bad data’ into the study. For example, systolic blood pressure must always be higher than diastolic blood pressure.
The more your data capture system can ensure the accuracy of data entry from the outset, the less you’ll have to clean and curate the data throughout the study. That said, oversights are inevitable, and strong curation will always be necessary.
It’s essential that the curation and communication be done in the system you’re using for data management. Managing large data sets and running centralized data curation (especially with multisite studies) is much easier — and far more reliable — using a flexible data platform.
When Should You Curate Data?
Early, regular, and continual data curation will help your study immensely.
Here’s an example:
The Issue
You’re conducting a multisite TBI study and late in the process, you notice a lot of results are missing from one of the sites. It’s a longitudinal study with different outcome measures that track patients’ recovery progress.
How is their mental and physical health, mood, spirit, coordination, cognitive ability, etc?
When you notice none of these measurements are being recorded at a particular study site, you contact them only to find out they have inadequate personnel at their facility to conduct follow-up assessments. At this point, the site is in danger of not collecting necessary data and invalidating the participants at that site.
The Solution
Early data curation can find an issue with the study in time to apply more resources or improve the process so these sites can execute the study protocol. Coordinating with the centralized data curation team, the sites now have an opportunity to collect the missing data according to the study protocol. If your research system natively has a ‘Timeline’ feature that tracks study progress for individuals or cohorts (versus the timeline being tracked in another system like MS Access), you can curate the data in your system focusing on the events and assessments that are currently due or past due.
The moral of the story: If you can curate early, you’re bound to discover things that will bolster and ensure the integrity of your study. Because regardless of the setup and mitigation you do to ensure proper data collection and entry, chances are you’ll never think of it all until it’s too late. Competent, early data curation goes a long way in preventing “too late.”
Who Curates the Data?
Data is most often curated by a centralized team of people with varying levels of responsibility. For some areas, you need subject matter experts. For others you don’t — someone to simply process the data is sufficient. As long as they understand the case report forms of the study and what the goals are, curators should be able to identify red flags and common inconsistencies that are necessary to clean the data.
With most clinical study curation, it is a combination of curators working in unison with doctors, nurses, and other subject matter experts to confirm, validate, or fix questionable data. For example, in TBI research, you may need ICU experts to set up specific queries for monitoring devices, but a centralized curation team can assure that the query results fulfill the criteria that were set up by the experts.
The Data Curation Loop
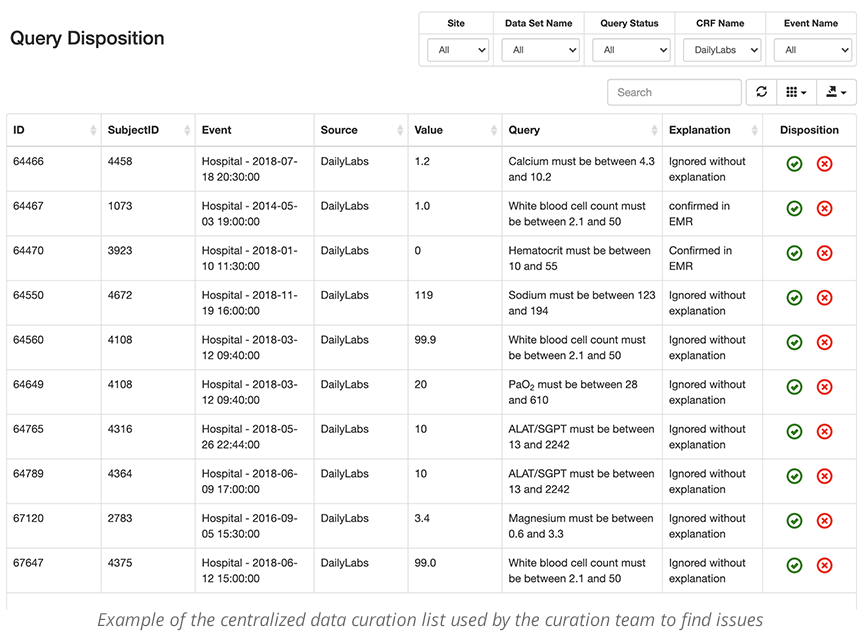
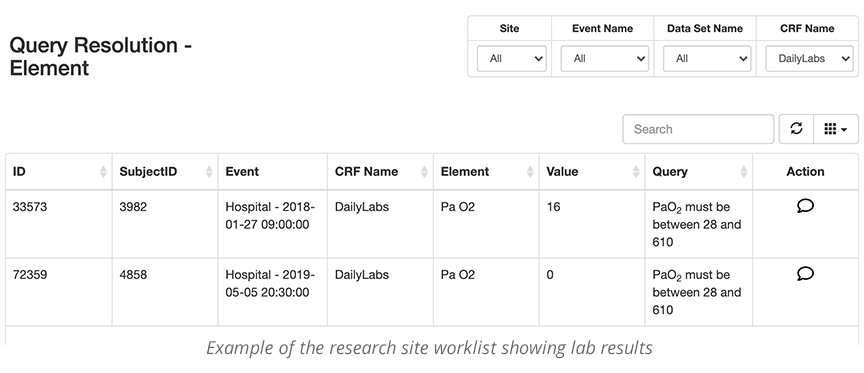
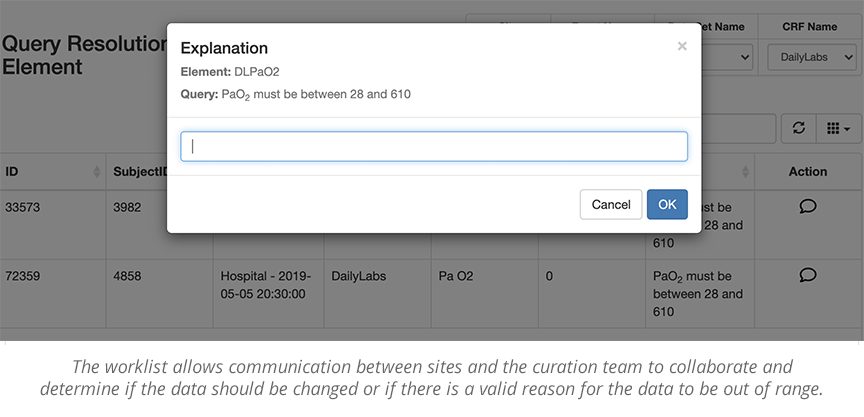
When curating data, it is very important to make the process as transparent and easy as possible. The site users and the data curator should be able to easily see the queries and data that they need to review, specific to their roles. The data curation and query management tool allows individuals to work from a single screen to curate the data. This is often called a worklist. Individuals in different locations can see and work from the same worklist. This is important when a study has many remote sites.
- Centralized data curation worklist
- Research site worklist
When issues are raised, the data curator worklist can be queried and filtered by eCRF, Subject, timeframe, etc., to check for completeness and accuracy. If potential red flags are reasonable and validated, the queries can be accepted and locked. If, however, they need more complete data, or the data needs further cleaning, it will be sent back to the site worklist for review.
Avoid Making Data Curation Too Complicated
Too often, data curation is turned into a very convoluted process. Imagine for every query or data set, having to:
- Pull the correct data out (query management)
- Analyze the data
- Find the issue and communicate it
- Transfer issues to a spreadsheet
- Send the spreadsheet to the site
- The site has to find the patient in the system
- Manually fix the problem
It may sound incredibly cumbersome, but it’s a regular occurrence in many research studies. The good news? Data curation doesn’t have to be so hard. The QuesGen platform transforms these seven time-consuming steps into one simple and continuous data curation loop.
We know how vital data curation is to your study, and we’re here to help.
